AIは、コンテンツの書き方から、単純なプロンプトから画像を生成する最近の開発まで、コンテンツの作成方法に革命をもたらした。LLM(大規模言語モデル)は大きく進歩した。ユーザーは、簡単なテキストベースのプロンプトを与えることで、リアルな画像を生成できるようになりました。これらの画像は、画像の著作権問題を心配することなく、プラットフォームを超えて使用することができる。AIによって生成された人間の画像も、自由に使用することができる。
このようなAIが生成した画像の応用可能性は無限である。しかし、日々新しいAI画像生成モデルが登場する中、最高のアウトプットを生成するのは厄介なことだ。この記事では、AIを使って画像を生成する方法をお伝えする。
AI画像生成とは?
簡単に言うと、AI画像生成は、テキストベースの説明的なプロンプトと参照画像を使用して、高品質の画像を生成します。画像を生成しながら、様々なスタイルや解像度を試すことができます。可能性は無限です。これらの画像はインターネット上の様々な画像から引っ張ってくるのではなく、高度なアルゴリズムを使ってゼロから作成されます。これは、シーンやシナリオを視覚的に想像し、それを再現する人間の能力を模倣したものです。
舞台裏では、見た目以上に多くのことが行われている。AIの画像生成は、ニューラルネットワーク、複雑な構造、人間の脳にインスパイアされたアルゴリズムによって支えられている。
AI画像生成で使用されるニューラルネットワークの最も顕著なタイプの1つは、Generative Adversarial Network(GAN)である。これは基本的に2つのモデルが一緒に働くもので、1つは画像を生成するもの、もう1つは生成された画像から実際の画像を区別するもので、ニューラルネットワークを完全に補完し、強化する。
初期のAI画像生成モデルは基本的なもので、人間の画像の生成、人種プロファイリング、テキストの生成などに欠陥があった。最近の開発により、これらの問題の多くが解決され、その領域は拡大する一方だ。近い将来、AIが生成した画像と実際の画像の区別はほとんどなくなるだろう(これはすでに現実のものとなっている)。
AI画像生成の仕組み
AIの画像生成はステップを踏んで行われる:入力処理、特徴抽出、画像生成、洗練、出力である。これらの各プロセスでは、異なるニューラルネットワークとアルゴリズムが利用され、それらを組み合わせることでAI画像生成モデルが形成される。
最初のステップである入力処理では、NLP(自然言語処理)能力を使用して、ユーザーからのテキストベースの入力を処理する。モデルのNLP能力は、キーフレーズを抽出し、さらなる処理のためのコンテキストを構築します。例えば、ユーザーがラフスケッチや参考画像を入力したとする。その場合、画像処理能力を使用して画像の主要な特徴を抽出し、テキストと画像を組み合わせてコンテキストを構築する。
第2のステップでは、特徴抽出にCNN(畳み込みニューラルネットワーク)を利用し、入力をさらに処理して画像生成モデルが理解できるようにする。CNNは、画像と入力フレーズから特徴を抽出し、画像生成のための接続と経路を確立する。これは画像生成のガイドとなるため、非常に重要である。
GAN(生成的逆数ネットワーク)を使った画像生成では、画像を生成するモデルと、生成された画像と実画像を区別するモデルの2つが互いに作用し、生成モデルをよりうまく機能させる。より高度な拡散モデルは現在、純粋なノイズをリバースエンジニアリングして画像を生成することに取り組んでいる。画像生成モデルは、これらの両方またはどちらか一方を使用することができます。
洗練と出力の最終ステップでは、AIを使う場合もあれば使わない場合もある。ほとんどのAIモデルでは、ユーザーが洗練プロセスを制御することもできます。生成された画像が洗練され、最終決定されると、ユーザーは最終出力を表示したり、様々な形式でダウンロードしたり、さらに使用するために他のツールにエクスポートしたりすることができます。
このような複雑なメカニズムが採用されているとはいえ、プロンプトの質と包括性はアウトプットに多大な影響を与える。
AI画像生成のためのステップ・バイ・ステップ・ガイド
AI画像ジェネレーターは一見使いやすそうに見えますが、それ以上にあなたのニーズをどのように定義するかが重要です。このガイドでは、あなたの要件に合ったものを選ぶ方法を説明します。
ステップ1: 適切なAI画像ジェネレータを選ぶ
使いやすさとアクセスのしやすさ:
●機能 気に入った画像ができても、編集もしたくなるかもしれない。携帯電話やPCにダウンロードするよりも、オンラインエディターの方が効果的です。このことを念頭に置いて、いくつかのプラットフォームは、画像編集、洗練、共有オプションなどの機能を提供しています。
●価格設定:ほとんどのモデルには、機能が制限され、生成速度が遅い無料層がある。最適なものを見つけるには、価格設定と長期的な全体コストも考慮する必要がある。モデルによっては有料モデルもあり、めったに使用しない場合に適しています。広範囲に使用する場合は、サブスクリプションが理想的です。
ステップ2:インプット/プロンプトを定義する
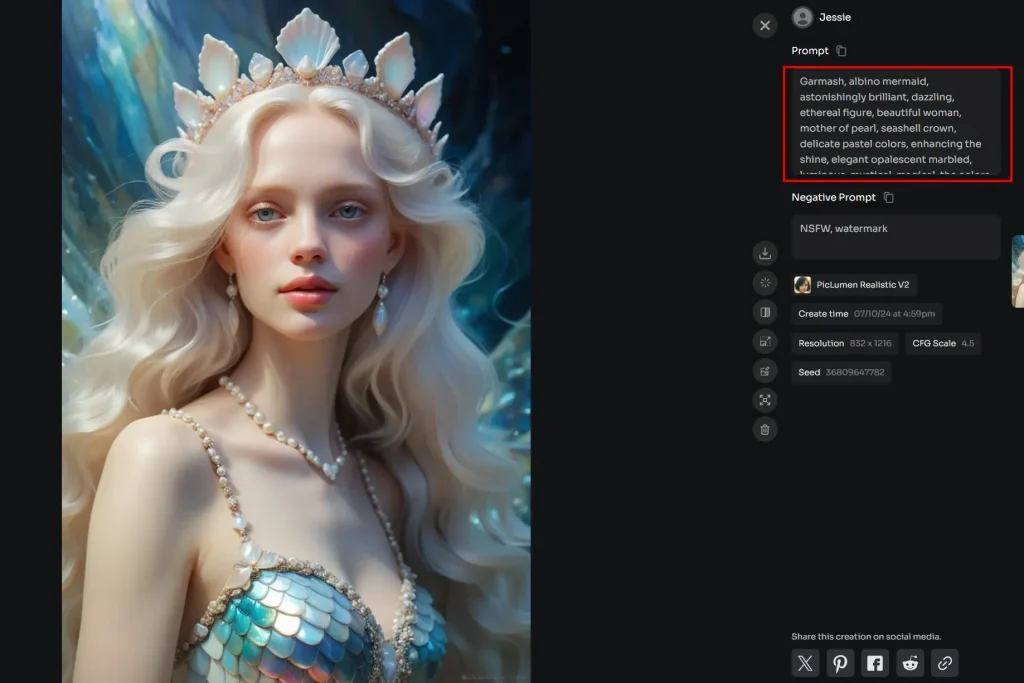
AIにどのように書き、ニーズを尋ねるかが重要だ。専門的にはプロンプトと呼ばれる。問い合わせ内容が明確であればあるほど、AIはより良いアウトプットを生み出すことができる。良いプロンプトは、以下の要素に分けることができる:
主題:イメージの核となる考え方。核となる対象や人物、あるいはイメージの本質を表す。
● アクション/ポーズ:被写体が何をしているかを表します。立っているのか、座っているのか、動いているのか。
●設定/背景:この部分は、画像の背景や情景を描写します。現在のAIモデルのほとんどは、あまりに詳細な背景を構築することが困難であるため、この部分は簡潔かつ鮮明にしてください。
● Style:画像のスタイルを記述することができます。多くのモデルでは、プロンプトにスタイルが含まれていない場合は、別途選択することができます。
●照明:
●その他の詳細:人物やキャラクターが持っているオブジェクトを定義することもできます。
上記の例を使ってプロンプトを構成すると、最終的なプロンプトはこうなる:神秘的な森の空き地で瞑想のポーズをとって座っている賢そうな老魔法使いを、ファンタジー・アート・スタイルで描く。柔らかな木漏れ日が魔法使いを照らし、彼は光るオーブを手にしている。
これがその結果だ。かっこいいでしょ?
ステップ3:設定とパラメーターの調整
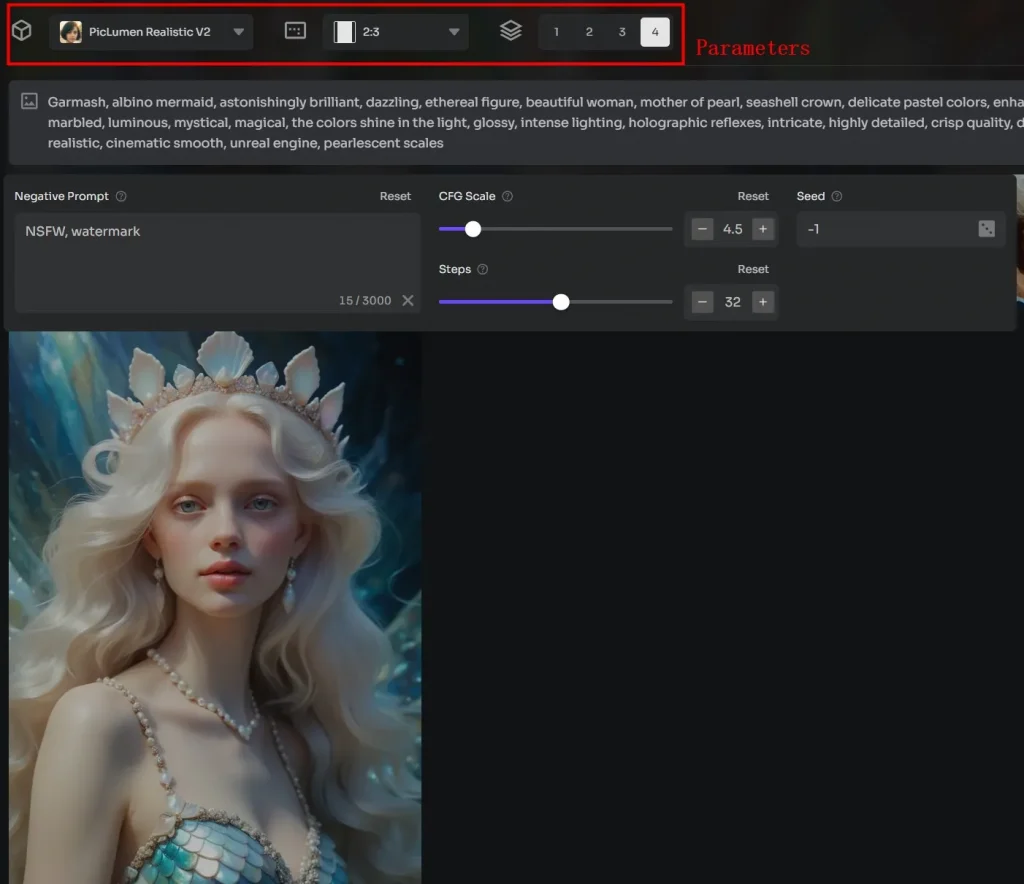
異なるAIモデルでは、それぞれの方法で設定やパラメーターを調整できる。しかし、ほとんどの場合、アスペクト比、画質、スタイル、画像数など、技術的な設定以外のさまざまな設定を調整することができます。あなたはそれに応じてそれらを選択することができます。モデルによっては、より高い解像度や多様なスタイルに追加料金を請求する場合があります。
ステップ4:画像の生成
これは自動処理です。生成ボタンをクリックするだけで、AIがアロガースムを使って画像を生成します。
ステップ5:見直しと改良
プロンプトを使って画像を微調整し、さらにカスタマイズすることも可能だ。画像に何かミスや好みに合わないものがあったときに便利だ。
ステップ6:ダウンロードまたはエクスポート
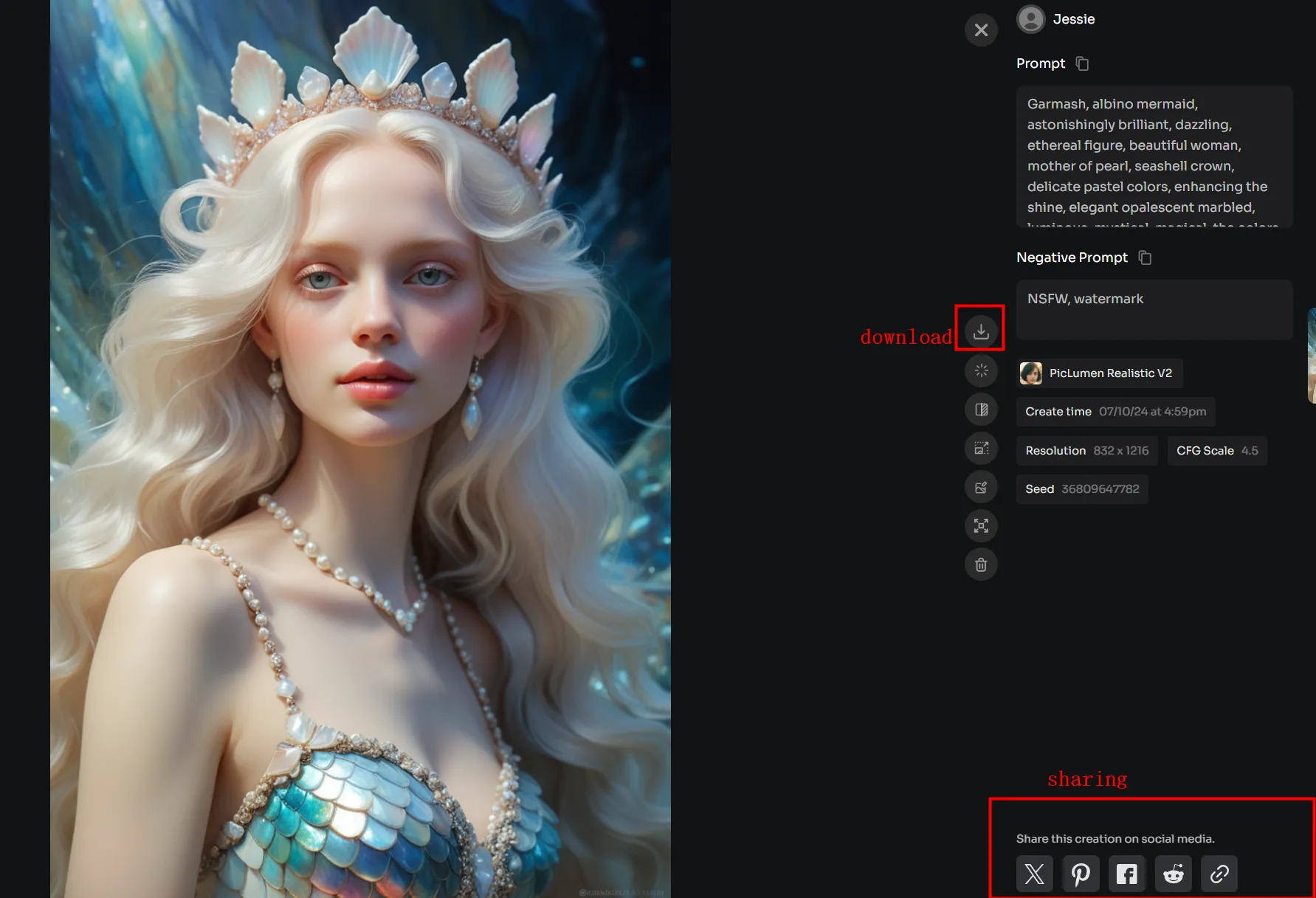
これが最後のステップで、生成された画像をダウンロードすることができる。Canvaのようなツールとの統合を提供するプラットフォームもあれば、これらの画像をデザインに使用できるプラットフォームもあります。お望みであれば、これらの画像をお好みの解像度でダウンロードすることができます。
AIはあなたが利用できる専門家であるが、適切な質問をすることが重要であることを忘れないでください。あなたがより正確で、明確で、有益であればあるほど、AIはより良いイメージを生み出すことができる。
まとめ
良いプロンプトの書き方が分かれば、あとは数回クリックするだけ。
以上、AIツールを使った画像生成についてでした。これから始める方は、PicLumenをご覧ください。数秒で高品質なAI画像を生成できる、市場で最も優れたツールのひとつだ。







